How to Set SLOs That Developers Actually Respect

Published on 26 March 2026 by Zoia Baletska
(Instead of “99.9% because Google does it.”)

Service Level Objectives (SLOs) have become a standard part of modern reliability engineering. They are supposed to help teams make informed decisions about reliability, prioritise work, and balance speed with stability.
Yet in many organisations, SLOs exist only on paper. They live in dashboards that nobody checks or in documentation that nobody remembers writing. Developers continue shipping features, operations teams continue firefighting incidents, and the SLOs quietly drift out of relevance.
A common reason for this disconnect is simple: the numbers were chosen arbitrarily. Someone picked 99.9% availability because it sounded professional or because a well-known tech company mentioned it in a talk.
Numbers like that rarely reflect the real behaviour of the system, the needs of the users, or the practical realities of development teams.
SLOs that developers respect are different. They are grounded in real service behaviour, tied to meaningful outcomes, and designed to support decision-making rather than decorate dashboards.
The Problem With Copy-Paste Reliability Targets
The internet is full of examples of SLO targets: 99.9%, 99.95%, 99.99%.
They look precise and reassuring. Unfortunately, they often come with very little context.
A target that makes sense for a global payment processor does not automatically make sense for an internal analytics tool. Similarly, a SaaS platform handling millions of daily requests will have different reliability expectations than a background batch job that runs once every night.
When teams copy targets without understanding the trade-offs, several predictable problems appear:
-
Targets become impossible to meet, which leads to teams ignoring them.
-
Targets become too easy, which means they fail to signal real reliability issues.
-
Developers treat SLOs as management metrics, not engineering tools.
Respect for SLOs starts with one principle: the number must reflect the system’s reality and its users’ expectations.
Start With What Actually Matters to Users
Before defining any percentages, it helps to answer a more fundamental question: What does a “good experience” look like for this service?
For many systems, reliability is not simply about uptime. It might include:
-
Request latency
-
Job completion time
-
API success rate
-
Data freshness
-
Queue processing delays
A data pipeline, for example, may be technically available all day but still fail its purpose if reports arrive six hours late.
By defining SLOs around user-visible outcomes, teams connect reliability metrics to real value.
This also makes SLO breaches easier to interpret. When an objective fails, it is clear what experience was degraded and why it matters.
Use Real Data, Not Aspirational Numbers
Another mistake teams make is setting targets before observing their systems. A better approach begins with baseline measurement.
Look at historical metrics:
-
Current availability levels
-
Typical latency ranges
Frequency and duration of incidents
This data reveals what the system already delivers under normal conditions. From there, teams can decide whether to:
-
Maintain the current reliability level
-
Improve it gradually
-
Accept lower reliability in exchange for faster delivery
Without baseline data, SLOs become guesses. With data, they become realistic targets that developers can work toward.
Translate SLOs Into Error Budgets
One reason developers engage with SLOs is when those objectives influence how work gets prioritised.
Error budgets are the mechanism that connects reliability targets to engineering decisions.
If a service has a 99.9% availability SLO, that leaves 0.1% downtime as an acceptable margin during a defined time window. This allowance becomes the error budget.
When the system stays within that budget, teams have the flexibility to release features, experiment, and move quickly. When the budget is exhausted, reliability work becomes the priority.
This structure changes the conversation. Instead of debating reliability in abstract terms, teams can make decisions based on measurable limits.
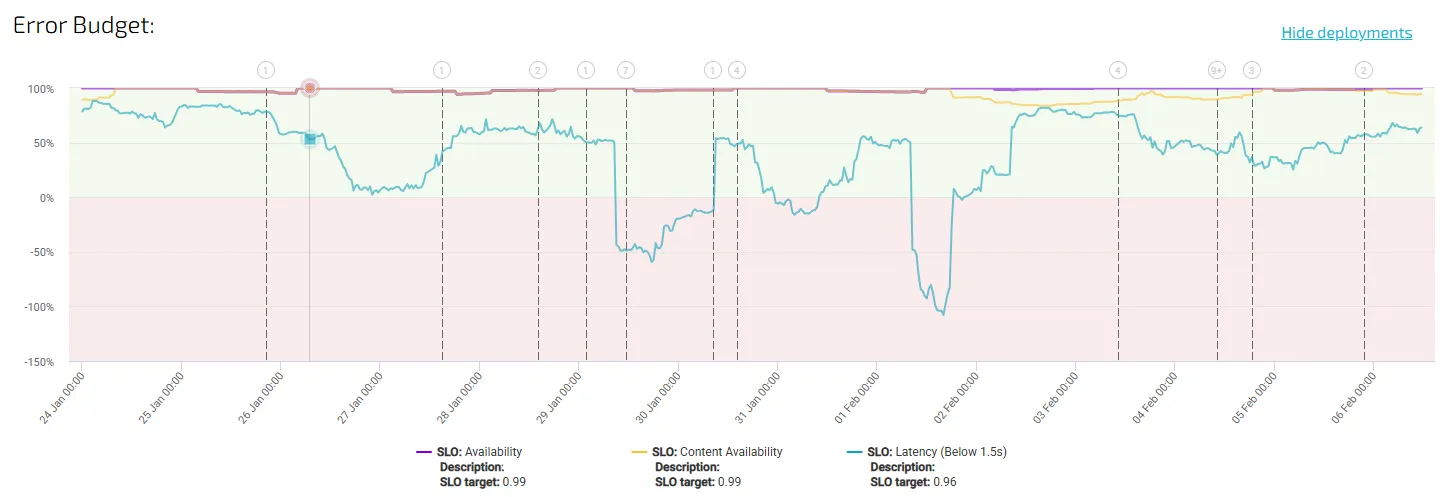
Error budgets transform SLOs from passive metrics into active governance for delivery speed and system stability.
Keep the Number of SLOs Manageable
Another reason SLOs lose credibility is simple overload. If every metric in a monitoring system becomes an objective, teams quickly stop paying attention. Developers cannot realistically track dozens of targets for every service.
Strong SLO practices focus on a small set of indicators that represent the health of the system. Typically, this includes metrics such as:
-
Availability
-
Latency
-
Error rate
-
Data freshness or job completion time
These signals are enough to detect meaningful reliability degradation without overwhelming engineers with noise. When an SLO fails, it should clearly indicate that something important is wrong.
Make SLOs Visible in Everyday Work
Developers rarely open reliability dashboards unless something is already broken. That is why SLOs must be integrated into the tools teams already use. Examples include:
-
Release pipelines that check error budget status
-
Incident dashboards that show current SLO health
-
Engineering planning sessions that review recent SLO performance
When SLO data becomes part of the daily workflow, it stops feeling like an external metric and starts guiding real engineering choices.
Platforms like Agile Analytics take this idea further by correlating reliability metrics with development activity, helping teams see how delivery practices influence service performance over time.
Expect SLOs to Evolve
Systems change. Architecture evolves. Traffic patterns grow or shift. SLOs that were reasonable a year ago may no longer reflect the current environment. Healthy teams revisit objectives periodically and adjust them based on:
-
New system capabilities
-
Changing user expectations
-
Improved infrastructure resilience
This process reinforces the idea that SLOs are living operational agreements, not static compliance targets. When developers see that objectives adapt to reality, they are more likely to treat them as meaningful engineering tools.
What Developer-Respected SLOs Look Like
When SLOs are working as intended, several patterns appear:
-
Engineers understand what the metrics represent.
-
SLO breaches trigger investigation and discussion.
-
Error budgets influence release decisions.
-
Reliability improvements compete with features in planning cycles.
In short, SLOs stop being theoretical and start influencing everyday work.
Reliability Targets Should Be Earned, Not Copied
Choosing 99.9% reliability because another company uses it rarely produces useful outcomes. Reliability targets only become valuable when they reflect the behaviour of a specific system and the expectations of its users.
Well-designed SLOs translate system performance into clear engineering signals. They help teams decide when to invest in stability, when to move faster, and where reliability improvements will actually matter.
When that connection is clear, developers no longer treat SLOs as external requirements. They treat them as tools that help them build better systems.
And that is when SLOs finally start earning the respect they were meant to have.
Supercharge your Software Delivery!
Implement DevOps with Agile Analytics
Implement Site Reliability with Agile Analytics
Implement Service Level Objectives with Agile Analytics
Implement DORA Metrics with Agile Analytics





