How to Break Into Site Reliability Engineering: Real-World Success Path

Published on 17 June 2025 by Zoia Baletska
Google birthed site reliability engineering in the early 2000s when software engineers took on the challenge of making large-scale sites more reliable, efficient, and expandable.
Software engineers solve operational problems differently through this innovative approach. SRE has become the industry-leading practice for service reliability, whatever the organization's size. The practice limits operational work to no more than 50% of an SRE's time, which keeps the focus on valuable engineering tasks.

SRE principles revolutionize organizations by creating expandable and highly reliable software systems. The growing complexity of interconnected systems makes concepts like error budgets, Service Level Indicators (SLIs), and Service Level Objectives (SLOs) crucial now more than ever.
In this piece, we'll show you a real-life success path to breaking into site reliability engineering. On top of that, our Agile Analytics platform can help you utilize data and experience. The platform reveals meaningful connections between team satisfaction and operational reliability to streamline processes.
Ready to begin your SRE trip? Let's take a closer look!
Start with the Right Mindset and Foundation
Modern organizations face an unprecedented volume of change and complexity in the tech world. These challenges substantially increase the risk of outages and incidents. Reliability has become the life-blood of modern systems engineering.
Why reliability matters in modern systems
Business continuity and customer trust depend on reliability. Studies reveal that companies with strong site reliability engineering functions reduce downtime by 50%[1]. These companies are 2.5 times more likely to meet their Service Level Agreements than others without. Reliability will give a solid foundation for data integrity, regulatory compliance, and user trust—essential elements of any successful digital service.
The philosophy behind SRE: automation over operation
SRE philosophy reshapes the scene by treating operations as software problems. Google's approach shows that SRE teams work with a vital principle: a 50% cap on operational work[2]. This thought-out limit lets engineers develop automation that makes systems "run themselves."
The SRE mindset emphasizes:
-
Automation over manual intervention
-
Engineering solutions rather than human workarounds
-
Using error budgets to balance innovation with stability
-
Applying software engineering principles to operational challenges
Teams can scale without adding more people while boosting system reliability with this approach. Organizations experience better stability, deeper understanding of production services, and higher staff morale.
Learning from the Google Site Reliability Engineering book
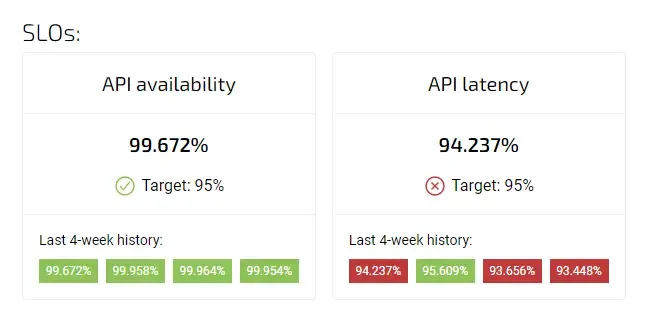
Google's SRE book provides great ways to get insights that shape successful reliability practices. One powerful concept states that "100% is the wrong reliability target for basically everything". SRE teams define appropriate Service Level Objectives (SLOs) and use error budgets to make smart decisions about development speed.
Agile Analytics tools help implement these principles effectively. You can spot meaningful patterns between team satisfaction and operational reliability by linking metrics like error budgets and SLOs with real-life team feedback. This evidence-based approach turns numbers into practical improvements that appeal to engineering teams.
Organizations build a foundation where reliability becomes an engineering discipline rather than just a reactive operational concern by embracing this mindset.
Build Your SRE Skillset Step-by-Step
A successful career in site reliability engineering demands expertise in specific technical concepts and hands-on skills. Let's look at the key elements that are the foundations of effective SRE practice.
Learn the principles: SLIs, SLOs, SLAs, Error budgets
Site reliability engineering centers around four connected concepts that measure and maintain system reliability.
Service Level Indicators (SLIs) measure service performance quantitatively. These well-defined metrics include availability, latency, error rates, and system throughput. A good SLI calculation works as a ratio: (number of good events) / (total number of events)[3]. This percentage format makes performance easy to understand.
Service Level Objectives (SLOs) set target values for your SLIs. Google's SRE practices highlight that "100% reliability is the wrong target for basically everything". SLOs help teams make analytical insights about reliability investments.
Service Level Agreements (SLAs) are contracts with users that specify consequences when SLOs aren't met[4], which often include financial penalties.
Error budgets round out this framework by setting acceptable failure thresholds. Our Agile Analytics platform connects these technical metrics with qualitative team feedback and shows how reliability affects user experience and team satisfaction.
Master observability and incident response
System health insights come from three key data sources:
-
Metrics: Quantitative measurements of system performance (CPU usage, memory, request latency)
-
Logs: Timestamped records of events providing chronological context
-
Traces: Complete request lifecycle data showing system interactions
A well-laid-out incident response follows a lifecycle: prevention through planning, monitoring for issues, and thorough investigation for resolution. Teams can move from reactive firefighting to proactive system improvements with this approach.
Get hands-on with tools like Prometheus, Grafana, and Terraform
SRE work requires skill with industry-standard tools:
Prometheus stands out at collecting time-series metrics with its pull-based model and powerful PromQL query language. Teams can monitor and alert in real-time to maintain their SLOs.
Grafana works with Prometheus to create visual dashboards. These visuals help teams spot patterns and anomalies in system performance quickly.
Terraform uses infrastructure-as-code principles to define infrastructure in simple text files. This automated approach reduces human error and keeps deployments consistent.
Your success in site reliability engineering depends on mastering these principles, practices, and tools. This knowledge builds a strong technical foundation for your career.
Apply Your Skills in Real-World Scenarios
Theoretical knowledge alone won't make you a successful site reliability engineer. Your growth happens when you apply SRE principles to solve actual problems. Here's how you can get practical experience and make meaningful improvements to system reliability.
Join open-source or internal reliability projects
Open-source projects are a great way to get practice with SRE skills in realistic environments. Cloud Operations Sandbox, an open-source platform based on Google's SRE practices, helps you adapt these principles to your cloud systems. Projects like Checkov (a static code review tool for infrastructure-as-code) and Litmus (a chaos engineering toolkit for Kubernetes) give you practical ways to detect vulnerabilities and improve system resilience.
PowerfulSeal helps you get hands-on chaos engineering experience by injecting failure into Kubernetes clusters to help spot issues quickly. These projects let you:
-
Find vulnerabilities before they affect production
-
Practice incident response in controlled environments
-
Learn how to fix deficiencies to improve system resilience
-
Customize tools to fit your specific architecture needs
Use Agile Analytics to connect metrics with team feedback
The gap between quantitative metrics and team experience is vital to SRE success. Our Agile Analytics platform connects technical measurements like error budgets and SLOs with ground feedback from your teams. This shows how reliability affects both user experience and team satisfaction.
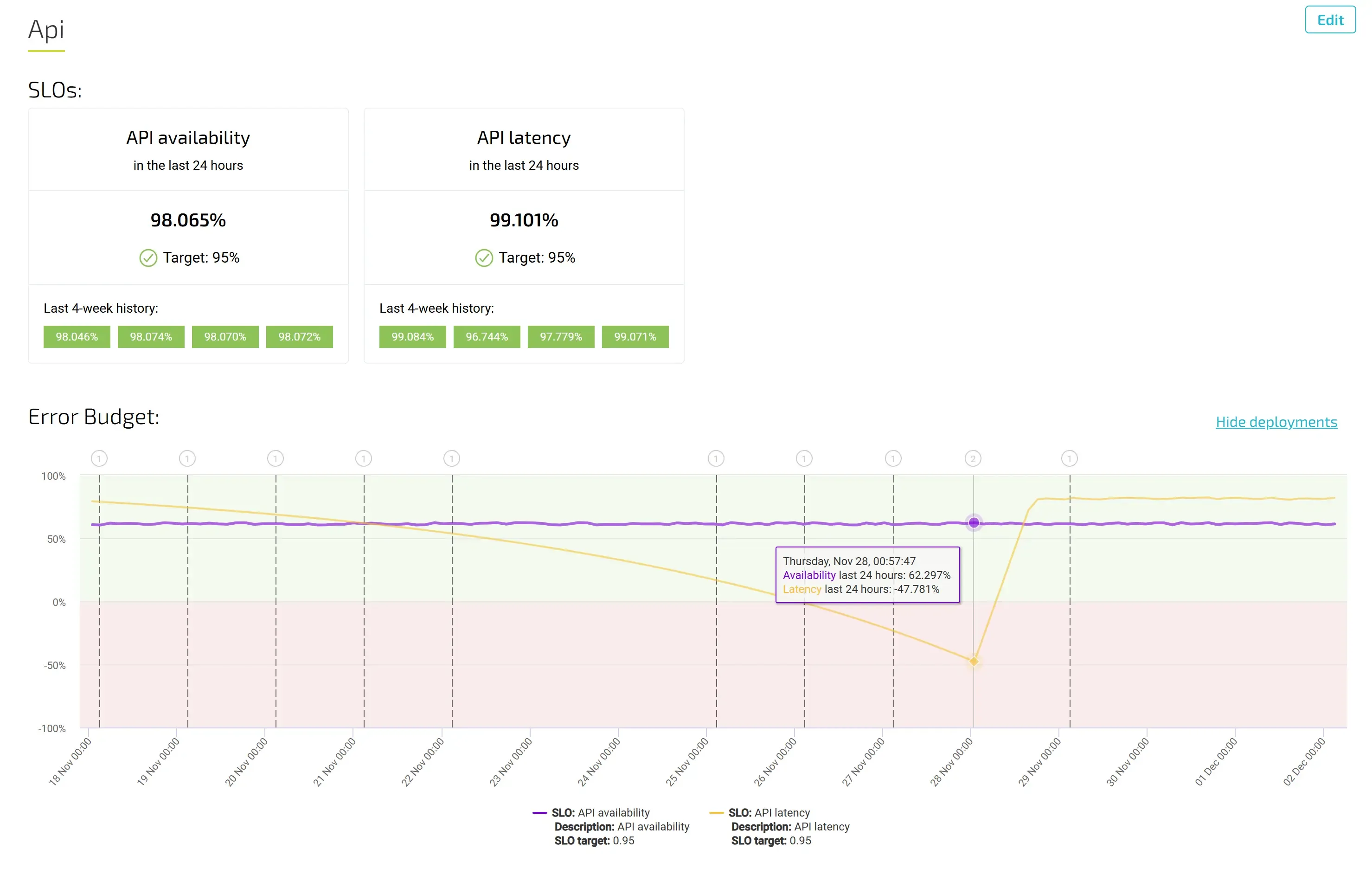
SRE teams should show value to both product teams (Development) and platform teams (IT operations). Measuring this value through key performance indicators (KPIs) shows areas to focus on and demonstrates business effects through metrics like change success rate, mean time to resolution (MTTR), and incident reoccurrence rate.
Check out how to set up your SLOs and start measuring Error budgets in Agile Analytics.
Turn insights into actions that improve system health
Good SRE teams don't just monitor systems—they make them better proactively. Regular service-oriented discussions about core metrics help you understand a system's performance envelope over time. Teams should track operational performance and link it directly to design, configuration, or implementation decisions during these discussions.
This feedback loop helps you spot gradual system changes that might go unnoticed otherwise. To implement improvements:
-
Assign specific action items to team members during production meetings
-
Track progress consistently to build credibility and trust
-
Include all stakeholders in discussions to ensure complete solutions
Careful application of SRE principles in real-life scenarios will build your practical experience. This helps advance your career while making meaningful contributions to system reliability.
Find Your First SRE Role and Grow
Your next step after building skills and applying them in ground scenarios is to land that first SRE position and plan your career growth. The path from aspiring to experienced site reliability engineer follows clear progression steps.
Where to look for site reliability engineering jobs
You need a smart approach to find site reliability engineering opportunities. Job boards like LinkedIn, Indeed, Glassdoor, and Dice list many SRE openings[5]. Company career pages often post jobs before they appear on these platforms. Getting in touch with technical recruiters who focus on DevOps or SRE roles can help you discover hidden opportunities.
SRE roles come in both on-site and remote options, with many companies embracing remote work. Tech companies, e-commerce platforms, and financial services companies value SRE skills highly.
How to stand out in interviews and technical assessments
SRE interviews combine technical evaluations with behavioral assessments. Make sure you can show your expertise in:
-
System design and architecture
-
Troubleshooting and incident response
-
Automation and scripting expertise
-
Monitoring tools and cloud platforms
Phone screens and technical interviews need you to explain your problem-solving approach clearly. Your thought process matters more than the solution. Our Agile Analytics platform helps you prepare by linking technical metrics with ground scenarios, giving you solid examples to share in interviews.
Growing from junior to senior SRE roles
Your career growth in site reliability engineering depends on expanding skills and responsibilities, not just time served. The typical path goes from Junior Site Reliability Engineer (0-2 years experience) to SRE Director (10+ years)[6]. Each level brings bigger challenges and needs deeper technical knowledge.
Success depends on growth in three key areas:
-
Responsibility: Tackling complex system reliability challenges
-
Realm of influence: Working with and affecting more stakeholders
-
Leadership: Building traits that spread reliability practices across teams
Senior SREs look at bigger pictures and business value instead of just technical details. Tools like Agile Analytics help spot important links between team satisfaction and operational reliability. This shows you know how to turn technical metrics into business wins.
Taking Your SRE Experience Forward
A successful site reliability engineer needs dedication, continuous learning, and practical application. This piece explores how SRE revolutionizes organizations. It creates flexible, highly reliable software systems while balancing operational work and engineering innovation.
Site reliability engineering has evolved beyond its Google origins to become vital across organizations of all sizes. The principles we discussed - from SLIs and SLOs to error budgets and incident response - turn reliability from an abstract goal into measurable, actionable practices.
The tools and techniques we covered are a great way to get practical implementation knowledge. You can build a strong technical foundation by becoming skilled at observability platforms like Prometheus and Grafana and infrastructure automation with Terraform. Open-source projects help solidify these skills and prepare you for real-life challenges.
Our Agile Analytics platform serves as a vital bridge between data and experience. It connects metrics like lead time, error budgets, and SLOs with qualitative team feedback. The platform reveals meaningful correlations between team satisfaction and operational reliability. These analytical insights help you make targeted improvements that strike a chord with your teams.
Success comes from balancing technical expertise with knowing how to communicate value, whether you're starting your SRE career or advancing to senior positions. The field keeps evolving but core principles stay constant: automate where possible, measure what matters, and prioritize reliability without sacrificing innovation.
Your SRE experience grows as you progress from junior to senior roles. It expands your responsibility, influence, and leadership. The skills you develop remain valuable as organizations recognize reliability as more than an operational concern - it's a competitive advantage in today's digital world.
Supercharge your Software Delivery!
Implement DevOps with Agile Analytics
Implement Site Reliability with Agile Analytics
Implement Service Level Objectives with Agile Analytics
Implement DORA Metrics with Agile Analytics