When Continuous Delivery Isn’t Possible: How Teams Can Still Improve Developer Experience

Published on 27 November 2025 by Zoia Baletska

Continuous delivery has become the holy grail in modern software development. The idea of shipping value to customers multiple times a day, collecting immediate feedback, and iterating rapidly is compelling. But for many software teams—particularly in hardware-heavy, regulated, or legacy-heavy domains—full continuous delivery (CD) is simply not feasible.
A recent paper by Eriks Klotins, Magnus Ahlgren, Nicolas Martin Vivald and Even-Andre Karlsson (2025), “When Continuous Delivery Is Not an Option”, explores how complex organisations navigate this reality. They show that while full end-to-end continuous software engineering (CSE) may be blocked by technical, organisational, or market constraints, teams can still achieve meaningful improvements internally. For DevEx, AgileEx, and OpsEx teams, these insights are highly actionable.
In this article, we’ll break down the paper’s key findings and outline practical steps for software teams to enhance developer experience and productivity—even when they can’t deploy continuously.
The Reality of Continuous Delivery in Complex Domains
The study examines four large organisations spanning industrial automation, automotive parts supply, retail e‑commerce, and chemical supply-chain software. The authors found a consistent pattern: even when teams are motivated to adopt continuous delivery, constraints often make it impossible.
Some of the most common constraints include:
-
Regulatory and safety requirements: e.g., safety-critical industrial systems cannot be deployed frequently without extensive verification.
-
Hardware coupling: embedded software in vehicles or machinery cannot be updated daily.
-
Supply chain dependencies: software often interacts with external systems or partners beyond the organisation’s control.
-
Organisational inertia: legacy systems, multiple silos, and outsourced teams can slow adoption.
At the same time, internal improvements—like automation of builds, tests, and integration pipelines—are usually feasible. This distinction between internal capabilities and external constraints is central to understanding what “continuous engineering” can look like in practice.
Updated Readiness Model for Continuous Software Engineering
The paper proposes an updated readiness model to help organisations assess what aspects of continuous engineering are achievable. It separates internal prerequisites (culture, processes, tooling) from external prerequisites (market demand, regulatory alignment, ecosystem dependencies) and highlights two distinct feedback loops:
-
Internal delivery loop: improving how the team builds, tests, and integrates software.
-
External product-use loop: improving how the end product is delivered, used, and iterated upon in the real world.
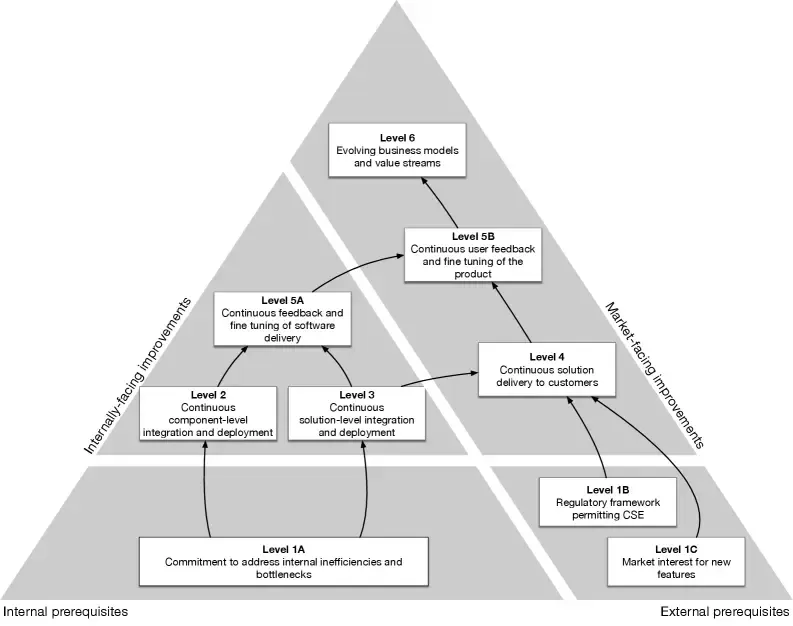
The updated industry readiness model (Source: https://arxiv.org/html/2511.02445v1)
The key insight: achieving full continuous delivery is often blocked by external factors, but internal loops can still generate significant value.
Lessons From the Four Case Studies
Here’s a brief look at the four organisations studied:
-
Industrial automation supplier: Safety-critical, hardware-software products. Continuous delivery to customers is infeasible. Focus is on component-level automation internally.
-
Automotive parts supplier: Long product lifecycles (25+ years), embedded software. Internal CI/CD is possible; field deployment remains constrained.
-
Global e-commerce retailer: More control over software delivery but limited by partner systems and legacy integrations. Partial continuous delivery is possible in some teams.
-
Chemical and supply-chain company: Software is not central, mostly outsourced, organisational readiness is low. Full continuous engineering stalled.
The takeaway: full end-to-end continuous delivery is often unrealistic, but internal improvements—automation, modularisation, testing, telemetry—remain actionable and beneficial.
Practical Recommendations for Teams
Even if you cannot deploy to production continuously, there’s still plenty you can do to improve developer experience, operational efficiency, and product quality.
1. Recalibrate ambition
Set realistic goals for continuous engineering based on organisational constraints. Instead of chasing daily deployment, focus on levels of maturity achievable within your environment. Use the readiness model to assess where your team sits and define your target.
2. Prioritise internal improvements
Internal loops are often under your team’s control. Focus on:
-
CI/CD automation: build, test, integration pipelines.
-
Modular architecture: decouple services for easier testing and deployment.
-
Test automation & coverage: catch defects early.
-
Metrics collection: build times, merge latency, defect injection rates.
3. Map external constraints
Identify dependencies in your ecosystem—suppliers, hardware, regulatory requirements, customer expectations—and adjust delivery expectations accordingly.
4. Align DevEx metrics with realistic goals
If you cannot deploy frequently:
-
Measure improvements in staging/sandbox environments.
-
Track reduction in build/test cycle times.
-
Measure manual release steps reduced, code integration pain points resolved, and test coverage improvements.
-
Use these as proxies for developer experience gains.
5. Communicate value incrementally
Highlight the benefits your team can control: faster internal feedback, reduced manual work, and higher code quality. Avoid framing progress solely as “we must deploy to production daily.”
6. Keep a long-term vision
Even if continuous delivery isn’t feasible today, prepare for the future by:
-
Building modular, instrumented, and decoupled systems.
-
Adding telemetry and versioning capabilities.
-
Planning for OTA updates or faster release cycles when external constraints loosen.
How This Relates to DevEx, AgileEx, and OpsEx
For teams focused on developer experience (DevEx), agile experience (AgileEx), and operational experience (OpsEx):
-
DevEx tools and strategy: Invest in automation, pipelines, and infrastructure that improve developers’ day-to-day workflow.
-
Developer experience measurement: Track build times, test flakiness, and merge latency. These are actionable and measurable improvements.
-
AgileEx practices: Even if production deployment is limited, frequent integration, incremental feature development, and internal feedback loops still support agile principles.
-
OpsEx metrics: Focus on stability, traceability, instrumentation, and supportability for existing systems.
The readiness model provides a framework for mapping your DevEx/DevOps improvements to what is feasible today, and planning incremental steps toward more ambitious continuous engineering goals.
Full continuous delivery may be blocked by hardware, regulation, organisational, or market constraints—but that doesn’t mean your team cannot benefit from continuous engineering. By focusing on internal improvements, mapping external constraints, and aligning developer experience metrics with realistic goals, software teams can make measurable progress.
The paper reminds us that continuous engineering is a spectrum, and even partial adoption delivers value. For teams in complex domains, the key is to improve what you can control, measure impact, and prepare for future opportunities when constraints loosen.
Supercharge your Software Delivery!
Implement DevOps with Agile Analytics
Implement Site Reliability with Agile Analytics
Implement Service Level Objectives with Agile Analytics
Implement DORA Metrics with Agile Analytics





