Why Your SLOs Might Be Failing (And How to Fix Them)

Published on 1 April 2025 by Zoia Baletska

Service Level Objectives (SLOs) are meant to keep your systems reliable, your customers happy, and your engineering team focused on what really matters. But what if your SLOs aren’t working?
Maybe your team is constantly firefighting incidents, or your error budgets run out too quickly. Maybe SLOs exist on paper, but nobody actually uses them to make decisions. If that sounds familiar, you’re not alone.
In this article, we’ll break down why SLOs often fail, share real-world examples, and give you practical solutions to turn things around.
Your SLOs Don’t Align with What Users Actually Care About
🔴 The Problem: Measuring What Doesn’t Matter
One of the biggest mistakes teams make is setting SLOs based on what’s easy to measure rather than what actually impacts users.
For example, let’s say you run a SaaS platform. Your SLO measures server uptime, but your real users care about page load times and API response speeds. Your system might be “up,” but if pages take 10 seconds to load, users will still churn.
✅ How to Fix It: Tie SLIs to User Experience
Your Service Level Indicators (SLIs) should reflect what actually impacts your customers. Instead of just tracking server uptime, consider:
-
Latency SLIs: How long does it take for key API calls to respond?
-
Availability SLIs: How often do users see an error when loading a page?
-
Throughput SLIs: How many transactions can your system handle per second?
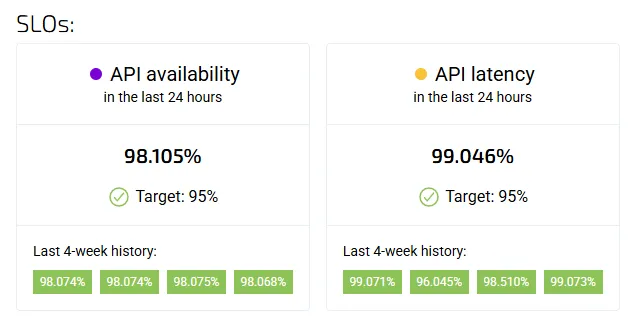
👉 Example Fix: Google SREs focus on a “golden signal” approach—tracking latency, traffic, errors, and saturation instead of just uptime. Following this model will give you a better picture of reliability from a user’s perspective.
Your Error Budgets Are Unrealistic (Or Ignored)
🔴 The Problem: Either Too Strict or Too Lenient
Error budgets help balance innovation and reliability, but many teams either:
-
Set them too aggressively (leading to constant incident panic), or
-
Ignore them completely (resulting in reliability chaos).
For instance, if your SLO demands 99.99% availability (four nines) but your team struggles to maintain 99.9%, you’ll burn through your error budget in days and be forced to halt feature releases. Conversely, if your error budget never runs out, your SLO is probably too lenient to be meaningful.
✅ How to Fix It: Make Error Budgets Actionable
-
Set realistic error budgets based on historical performance, not wishful thinking.
-
Tie error budget consumption to decision-making. If your budget runs out, prioritize stability work over new features.
-
Regularly review error budget usage in sprint planning to make adjustments before things get critical.
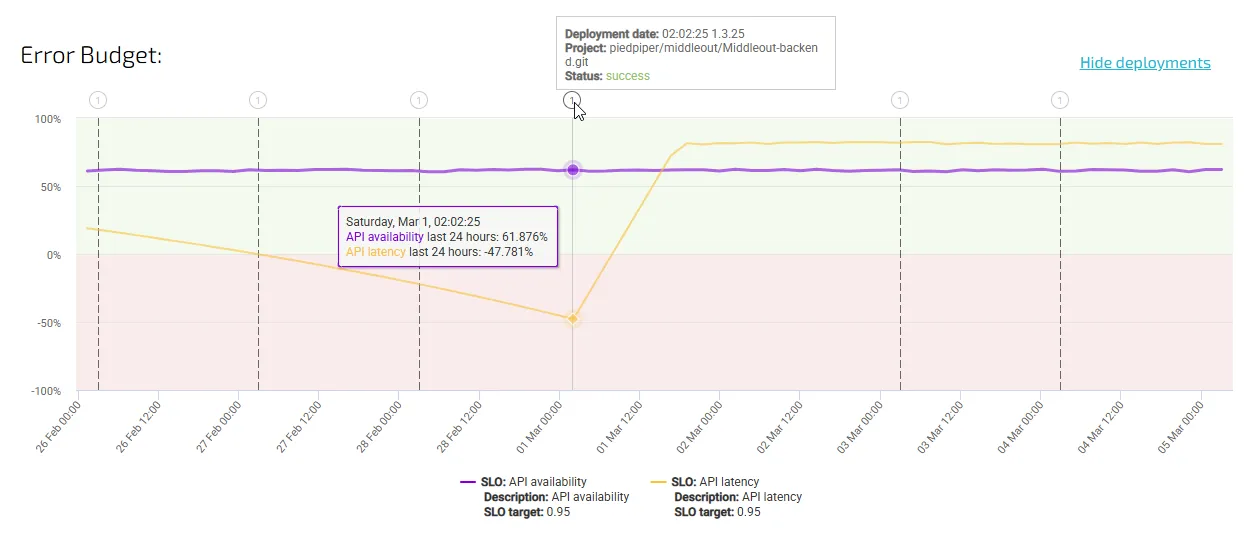
👉 Example Fix: Netflix SREs use error budgets as a feature throttle. If a service exceeds its error budget, teams pause risky changes until reliability improves. This prevents firefighting and encourages long-term system health.
Your Team Treats SLOs as a Reporting Exercise, Not a Decision-Making Tool
🔴 The Problem: SLOs Exist on a Dashboard, But Nobody Uses Them
Many organizations treat SLOs as something to report to leadership rather than a tool for making smart trade-offs.
If your SLOs are just static numbers in a dashboard with no real impact on engineering priorities, they’re failing.
✅ How to Fix It: Integrate SLOs into Daily Work
-
Use SLOs in on-call playbooks. If an incident occurs, don’t just fix it—ask, “Did we burn a significant part of our error budget?”
-
Tie SLOs to product decisions. If a new feature is causing reliability issues, use SLO data to decide whether to proceed or pause development.
-
Automate alerts when SLOs are breached. Don’t wait for a quarterly review—flag potential breaches early and act before customers feel the pain.
👉** Example Fix**: Google’s SRE team famously treats SLO breaches as a call to action. Instead of just recording the breach, teams shift priorities toward fixing reliability issues before they spiral out of control.
Your SLOs Are Too Rigid and Don’t Evolve with Your Business
🔴 The Problem: “Set It and Forget It” Mentality
our business changes, your customers change, and your infrastructure changes— but do your SLOs keep up?
If you haven’t updated your SLOs in over a year, chances are they’re outdated and don’t reflect your current reality.
For example, maybe your app started as a small B2B tool, and 1-second latency was acceptable. But now, your company serves millions of consumers, and fast response times are critical.
✅ How to Fix It: Regularly Review and Adapt SLOs
-
Reevaluate your SLIs every 6–12 months. Ask: Are these still the best indicators of user experience?
-
Adjust SLO targets based on user expectations. If competitors are offering better performance, you might need to tighten your targets.
Make SLOs Work for You, Not Against You
SLOs should be practical tools that drive better engineering decisions — not just vanity metrics for reports. If your SLOs aren’t helping, ask:
-
Are they truly user-focused?
-
Are they ambitious but realistic?
-
Are error budgets being used proactively?
-
Are they informing real engineering decisions?
-
Are they being reviewed and updated regularly?
By shifting how you approach SLOs, you’ll turn them from frustrating obligations into powerful levers for reliability, innovation, and customer success.
Want to track, refine, and optimize your SLOs the right way? Check out how Agile Analytics can help! 🚀
Supercharge your Software Delivery!
Implement DevOps with Agile Analytics
Implement Site Reliability with Agile Analytics
Implement Service Level Objectives with Agile Analytics
Implement DORA Metrics with Agile Analytics